ai
Developing Agentic Harnesses

Notes from the road, after three architectures and one honest reset.
Why I’m writing this
Over the last three months I’ve shipped three different “brains” for the same product. Same backend, same database, same set of tools — but three completely different ways of letting a language model decide when to use them. Each time I shipped, I learned something I hadn’t seen before. Each time I pulled back, it wasn’t because the previous architecture was wrong — it was because I’d discovered a constraint that wasn’t visible when I started.
This is a post about that journey. It’s not a “we cracked it” post. There is no clean ending. The honest answer is that agentic development right now is the work of finding the right tradeoff between three primitives, and that tradeoff moves every time you change the model, the toolset, or the data.
The three primitives are:
- Right answer — the agent gives a correct, complete, verifiable response
- Right security — the agent does not leak data it shouldn’t, and does not take actions it isn’t authorized to
- Right performance — the agent gets there in a reasonable number of tool calls, in a reasonable amount of time, at a reasonable cost
Beneath all three is one foundational truth: the agent must not hallucinate. Not “must not hallucinate often.” Must not hallucinate. If you cannot trust what the agent reports as fact, none of the other three primitives matter — you have a confident liar, and a confident liar is worse than no agent at all.
Above the three primitives are two secondary needs: personality (the agent should feel like yours, not a generic assistant), and self-improvement (the agent should get better the more it works with you, not just the more the foundation models improve). These are real, but they’re luxuries until the three primitives are solid.
And underneath everything is the data. In my case, that data lives in a knowledge graph. The agent is only as good as that graph is accurate, complete, and current. An agent on top of a stale or sparse graph will look broken even when the agent itself is fine — and a lot of the journey below is the slow realization that some “agent bugs” are actually graph bugs in disguise.
The journey, in three movements
Movement one: trust the model, give it everything
The first version was the simplest thing that could possibly work. One LLM. All the tools. Every turn, the model saw the full toolbelt and decided what to do. We added a thin semantic layer on top to narrow the knowledge graph queries — call it a graph-aware tool selector — but the architecture was basically: let the model think, give it everything it might need, and trust it to pick well.
It worked surprisingly well. For most queries, the model picked sensible tools, chained them in sensible ways, and produced answers I could verify. But three problems showed up:
- Cost. Sending 90+ tool definitions in every prompt is expensive in input tokens, and the bigger the prompt, the worse the prompt cache hits.
- Distraction. When the model can see every tool, it sometimes chose the wrong one — reaching for an exploration tool when a direct lookup would have done.
- Containment. A query about “promotions” could send the model on a 40-tool-call expedition through emails, meeting notes, and document content, looking for personnel data. Even if no data leaked, the exploration itself was a problem: it was slow, expensive, and looked like a security incident even when it wasn’t.
The right answer was usually there. But the right path to that answer wasn’t always.
Movement two: route the model into a smaller world
So we built a router. Different categories of query — operational tasks, knowledge graph research, external write actions, scheduled jobs, sensitive personnel topics — each got their own “domain” with a curated subset of tools and a domain-specific prompt. The model didn’t see 90 tools anymore. It saw 5–25, depending on where the router sent it.
This solved the cost problem and the containment problem. Personnel queries now had a hard exploration limit. Token usage on the average turn dropped significantly. Cache hit rates went up. The agent felt sharper.
But it introduced new problems we hadn’t predicted:
- Cross-domain workflows broke. A user might ask about an initiative, then say “now put that in a Google Doc.” The second turn was routed independently — and “now put that in a doc” alone didn’t always match the right pattern, so the doc tools weren’t in scope. The model honestly reported “I don’t have those tools” — and from the user’s perspective, the agent had just forgotten something it knew a moment ago.
- Continuity needed real machinery. Pronouns, follow-ups, and implicit context are easy for humans and hard for routers. A router that re-evaluates from scratch on every turn is fast but forgetful.
- The model started under-calling. With a smaller toolset and a tighter prompt, the model became more conservative about chaining. Queries that previously fanned out into 3–4 tool calls now stopped at 1, sometimes producing terse half-answers.
The first version had been too loose. This one was too tight. And we couldn’t tune our way out of it just by widening the tool lists, because then we’d be back where we started.
Movement three: bring in a reasoning loop
The next move was to wrap the routed agent in a more explicit reasoning loop — closer to a ReAct-style controller. The model would think, act, observe, think, act, in named steps. The loop tracked tool families, enforced “inspect before write,” guarded against capability denials, and gave us a place to plug in retries, scratchpads, and per-domain step caps.
For the queries that matched the controller’s worldview, this was a beautiful upgrade. Personnel containment got tighter. Multi-step analysis flows became reliable. The controller surfaced why the agent did what it did, which was a huge debugging win.
But for everyday queries — “show me my initiatives,” “draft an email,” “what’s blocking Enpro” — the controller was too much. The agent became more thorough but also slower, sometimes by a factor of three. Tool call counts went up, not down, because the controller’s “thoroughness” pushed the model to fetch more than necessary. A query that used to take 9 tool calls would take 90 because the controller dutifully chained get_detail for every result of a list query.
I was solving a containment problem by adding ceremony. The ceremony cost more than the containment saved.
Movement four (the present): back, but not where I started
So I’m back on the simpler architecture — the trusted-model approach from movement one — but now with the lessons from two and three baked in: targeted security gates instead of blanket scoping, per-domain step caps where they matter, smarter tool descriptions so the model chains naturally instead of being commanded to. The router still exists, but it’s advisory in some places and enforcing in others, depending on what the data tells us.
The point isn’t that “simple won.” The point is that I now know what the simple architecture costs me, and I know which of those costs I can live with. That’s something I didn’t know on day one. I had to ship the harder versions to learn it.
The three primitives, revisited
This is where I want to slow down, because I think this is the actual lesson.
Right answer is not the same as “the model said something that sounded right.” Right answer means: every claim in the response is traceable to a tool result, and every tool result is from a source you trust. The day you stop being able to draw that line, you’ve lost the foundational truth.
Right security is not the same as “we redact PII before showing it to the user.” Right security means: the agent never retrieves data it shouldn’t see, never writes to a system it shouldn’t touch, and never takes an action the user didn’t approve. The hardest part isn’t the redaction — it’s reasoning about what an agent can do transitively through a chain of tool calls you can’t enumerate in advance.
Right performance is not the same as “responses are fast.” Right performance means: the agent uses the smallest viable set of tool calls, doesn’t repeat work it’s already done, and degrades gracefully under load. A response that takes 90 seconds because it actually needed 90 seconds of work is fine. A response that takes 90 seconds because the agent looped on the same exploration four times is not.
These three are in constant tension. Tighten security and you slow things down. Optimize for performance and you risk under-fetching the answer. Push for completeness and you blow the tool budget. The three primitives form a triangle, and every architecture decision is a movement inside that triangle, not a way out of it.
Honesty before everything
Underneath the three primitives is the foundational rule, and it’s worth saying twice: don’t hallucinate.
A hallucinating agent fails all three primitives at once. A “right answer” that was made up is not a right answer. A security gate doesn’t matter if the agent invents the data. A performance optimization that lets the agent answer faster from its imagination is the worst kind of speedup.
The practical implication is that every claim the agent makes should be tied to a real tool call. If a tool call didn’t happen, the answer doesn’t exist. If a tool call returned no data, the answer is “I don’t have that,” not a confident guess based on prior knowledge. This sounds obvious. It is not what most agents do by default. You have to build it in deliberately, and you have to test it constantly, because it’s the easiest invariant to lose.
Personality and self-improvement, the secondary layer
Once the foundation is solid, you start to want more. You want the agent to feel like yours — to know your tone, your priorities, your shortcuts, your team. And you want it to get smarter from working with you, not just smarter when the next foundation model drops.
These are real and they matter. They are also the first things to break when the underlying primitives are unstable. A “personality” layered on a hallucinating agent is a quirky liar. A “self-improvement” loop on top of an insecure agent is automated risk accumulation. Get the primitives right first, then add the soul.
And underneath everything: the data
Most of the bugs I traced to “agent behavior” turned out to be data bugs. A graph that’s missing 30% of its relationships will make the model look like it can’t reason. A graph with stale entity types will make the model look like it doesn’t know how to filter. A graph where two entities have the same name and no disambiguation will make the model look like it’s confusing people.
The hardest lesson of the year was that agent quality is bounded above by graph quality, and the work of monitoring the graph for accuracy and depth is at least as important as the work of tuning the agent on top of it. We now treat graph health as a first-class observability concern: drift, missing relationships, stale extractions, type coverage. If the graph rots, the agent rots with it — and the rot is hard to see because the agent will still produce confident-looking answers.
What everyone else is doing
I’m not the only person working through this. The frame I want to push back on is the “framework wars” framing — the idea that this is a zero-sum race between Anthropic and OpenAI and the open-source crowd. It’s not. We’re all running into the same wall in different shapes, and we’re all learning from each other.
Anthropic has been steadily formalizing the agent loop with the Claude Agent SDK and Skills. Their bet is that a standardized “skill” — a folder with instructions, scripts, and resources that loads on demand — is the right unit of agent capability. They’ve also pushed the Model Context Protocol hard as a way for agents to discover and authenticate against external tools without bespoke integration code. The throughline is containment through composition: small, well-defined units that the agent loads only when relevant.
OpenAI started with Swarm as an experimental framework, then graduated it to the Agents SDK with built-in tracing, guardrails, and tighter integration with the Responses API. At DevDay 2025 they introduced AgentKit with a visual workflow builder. Their bet is that agents are workflows, and workflows benefit from being designable, inspectable, and exportable. The throughline is clarity through structure.
OpenClaw, the open-source upstart, took a completely different route. Instead of optimizing for the API → tool-call → response loop, OpenClaw treats the agent as a persistent daemon that lives in your messaging apps and on your machine, with memory stored as Markdown files you can read and edit yourself. It crossed 100,000 GitHub stars in its first week for a reason: it’s local-first, user-owned, and radically transparent. The throughline is sovereignty through openness.
These are three different bets. Containment through composition (Anthropic), clarity through structure (OpenAI), sovereignty through openness (OpenClaw). None of them is the answer. All of them are pulling on different corners of the same triangle — the right-answer / right-security / right-performance triangle — and we are all watching each other and stealing the good ideas.
I steal from all three. The skill-as-capability idea is a beautiful primitive. The traceable workflow idea is a beautiful primitive. The local-first markdown memory idea is a beautiful primitive. None of them, alone, solves the problem I’m working on. Together they hint at the shape of what’s coming.
The honest summary
If you’re building agents right now, here is what I would tell my three-months-ago self:
- Ship the simple version first. You will not know what you don’t know until you watch the simple version fall over in production.
- Don’t add ceremony unless you can name the bug it fixes. Routers, controllers, scratchpads, and reasoning loops all have a cost. If you can’t point to a specific failure they prevent, they’re tax.
- Treat the three primitives as a triangle, not a checklist. Every change moves you inside the triangle. There is no architecture that maximizes all three at once.
- Test the foundational truth constantly. Have a small set of scenarios that catch hallucinations, capability denials, and over-exploration, and run them every time you change anything. Ours is 20 scenarios. It’s not enough, but it’s better than zero.
- Watch your data the way you watch your code. A regression in graph coverage is functionally identical to a regression in your agent code. Both will show up as “the agent got worse this week.”
- Read what everyone else is doing. Anthropic, OpenAI, OpenClaw, the open-source community — they are all running this same gauntlet from different angles and you will save yourself months by stealing the parts that fit. This is not a zero-sum game. We are all learning the shape of the same wall.
The work isn’t done. The architecture I’m running today will not be the architecture I’m running in three months. That’s fine. The point of agentic development right now is to keep moving inside that triangle, deliberately, with the foundational rule held constant: never let the agent lie to the user. Everything else can be tuned. That, you protect.
Sources I read while writing this:
- Building agents with the Claude Agent SDK — Anthropic
- Equipping agents for the real world with Agent Skills — Anthropic
- Claude Agent SDK overview — Claude API Docs
- New tools for building agents — OpenAI
- OpenAI Agents SDK documentation
- OpenAI Extends the Responses API to Serve as a Foundation for Autonomous Agents — InfoQ
- OpenClaw — Personal AI Assistant
- OpenClaw on GitHub
- What is OpenClaw? — DigitalOcean
Related articles
-
ai
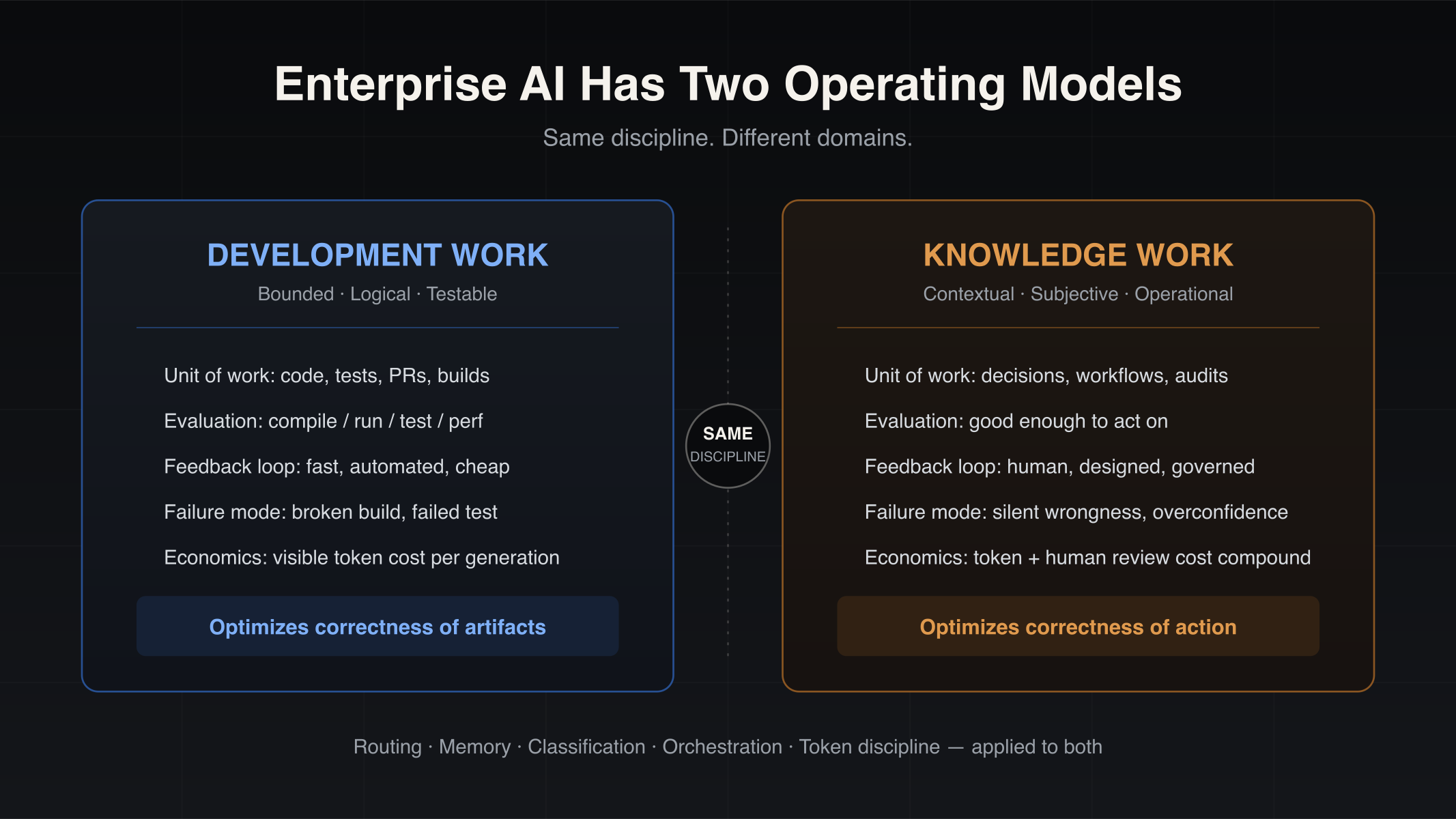
Enterprise AI Has Two Operating Models: Development Work and Knowledge Work
Enterprise AI is splitting into two operating models — development work and knowledge work. Why coding-copilot playbooks stall on operational workflows, and which engineering disciplines transfer.
-

ai
Jira-to-GitHub Issues Migration Using BMAD: Lessons from the Implementation
A practical account of migrating Jira tickets to GitHub Issues using BMAD, including lessons on planning, testing, user mapping, pagination, and content conversion.
-
ai
Tokenomics Is the New AI Efficiency Frontier — and Here's How We're Winning It
AI tokenomics is the discipline of managing token consumption at enterprise scale. Learn how semantic infrastructure, context-aware retrieval, and agent budgeting cut AI costs without sacrificing quality.