ai
Tokenomics Is the New AI Efficiency Frontier — and Here's How We're Winning It
Tokenomics Is the New AI Efficiency Frontier — and Here’s How We’re Winning It
By Rohit Garewal, CEO, Object Edge
“The question is no longer whether AI can reason — it’s whether you can afford to let it think inefficiently.”
There’s a conversation happening in boardrooms and engineering teams right now that isn’t about model capability. It’s about cost discipline. The word gaining traction is tokenomics — and if you’re deploying AI at any meaningful scale, you need to understand it before your next infrastructure bill does.
Let me explain what it is, why it matters, and how we’ve built Hive and Sayya specifically to address it.
What is AI tokenomics?
In the context of large language models, a token is the atomic unit of computation. Every word you send to a model, every chunk of document context, every tool result that flows back into the reasoning loop — it all costs tokens. At small scale, this is invisible. At enterprise scale, it becomes a primary operating variable.
Tokenomics is the discipline of managing that variable intentionally: optimizing what gets sent to the model, when, how much, and in what form — so you get maximum intelligence output per token spent.
This is not about cutting corners. It’s about engineering precision. The same way financial discipline separates sustainable businesses from cash-burning ones, token discipline will separate high-performing AI organizations from the ones that build impressive demos but can’t survive production.
Why most enterprise AI implementations bleed tokens
The default pattern for enterprise AI is naive: stuff as much context as possible into every prompt, hope the model figures it out, and call it a day. The results are predictable — high latency, high cost, inconsistent quality, and brittle behavior when context windows fill up.
The root cause is a lack of semantic infrastructure. When an AI agent doesn’t know what it knows — when it has to brute-force search, re-read entire documents, and re-resolve the same entity relationships on every call — token waste is structural, not incidental.
The fix isn’t a better model. It’s a smarter architecture.
This isn’t a problem you can outrun by waiting for prices to drop, either. As we covered in The End of Subsidized Tokens Is Coming. Plan Accordingly., the era of artificially cheap inference is ending. The organizations that build token discipline now will be the ones still standing when the subsidies disappear.
How Hive was built around token efficiency
We’ve optimized token usage across our enterprise by building two tools:
- Hive, our semantic knowledge layer that leverages an ontology to create semantic embeddings about all of our structured and unstructured data. Today’s article is about how Hive helps us optimize tokens.
- Sayya, our agentic harness, which is optimized to leverage both frontier models and open-weighted international models in order to cut token costs by over 1,500%. How we do that on Sayya will be an upcoming article.
Hive is our AI-native operating platform, and its core layer is a semantic knowledge graph — a live, queryable representation of your organization’s entities, relationships, memories, and context.
The practical impact on tokenomics is significant. Instead of passing raw documents and unstructured data into every prompt, Sayya (our AI copilot layer) pulls pre-resolved, structured context from the knowledge graph. A question about a client account doesn’t trigger a document search — it traverses a graph that already knows the account’s relationships, recent activity, open tasks, and historical decisions.
The innovations we’ve leveraged to make this work:
1. Context-aware retrieval, not full-document injection
Rather than injecting full transcripts, emails, or records into every prompt, Hive retrieves only the semantically relevant subgraph. A question about an account’s renewal risk surfaces the relevant contracts, stakeholder notes, and open blockers — not the entire account history.
2. Episodic memory with selective recall
Sayya maintains episodic memory tied to users, accounts, and initiatives. On every turn, a lightweight planning model determines which memories are relevant before the main reasoning call. The result: the primary model sees a pre-filtered, high-signal context window rather than a bloated one.
3. Tool-budgeted multi-agent orchestration
When Sayya orchestrates multi-step workflows — running playbooks, generating reports, monitoring KRs — it does so with a tool-budget discipline. Each sub-agent call is scoped to the minimum context required to execute its task. Agents don’t share full state unless they need to; they share only what’s necessary for the next step.
4. Structured output over free-form reasoning
Where possible, Hive routes analytical questions through structured query engines — knowledge graph queries, aggregations, pre-computed reports — rather than asking the LLM to reason over raw data. The model is invoked for synthesis and judgment, not arithmetic or entity resolution, where structured tools are more accurate and dramatically cheaper.
5. Semantic pre-filtering via the planning layer
Before any user question reaches the main model, a planning layer reads the current page context, recalled memories, and organizational schema to route the query to the right tool with the right scope. This eliminates speculative, wide-net context retrieval — a major source of token waste in naive RAG implementations.
The business case is compounding
Here’s what makes tokenomics a strategic lever, not just an infrastructure concern: the savings compound with scale.
An organization running 500 AI-assisted workflows per day — account reviews, task triage, status reports, client briefings — sees token waste accumulate linearly with every inefficient prompt. Our architecture means each workflow runs leaner, faster, and more accurately than a naive implementation. As usage scales, the efficiency gap widens.
Beyond cost, there’s a quality argument. Context windows that are smaller and better-curated produce more reliable outputs. Less noise means less hallucination, tighter reasoning, and responses that actually match what the user asked. Token efficiency and output quality are not in tension — they reinforce each other.
What this means for your AI strategy
If your organization is scaling AI usage, ask three questions:
- Are you measuring token consumption per workflow? If not, you’re flying blind on one of your core AI operating costs.
- Is your context retrieval semantic or brute-force? Full-document injection is a smell. You should be able to answer most queries from a structured graph or pre-filtered memory, not a full text sweep.
- Are your agents context-disciplined? Multi-step orchestration should minimize shared state, not maximize it. Each agent call should carry exactly what it needs.
These are the questions we asked when building Hive. The answers shaped an architecture that treats tokenomics not as an afterthought but as a first-class design constraint.
The path forward
The AI efficiency frontier is shifting fast. Model costs are declining, but usage is growing faster. The organizations that build semantic infrastructure now — knowledge graphs, episodic memory, context-aware retrieval — will have a durable advantage over those still injecting raw data into LLM calls at scale.
Tokenomics isn’t a trend. It’s a discipline. And like all disciplines, it rewards early commitment.
Rohit Garewal is the CEO of Object Edge, an AI-native professional services firm. Object Edge builds Hive, a semantic intelligence platform that helps enterprise organizations operate with AI at their core.
Related articles
-
ai
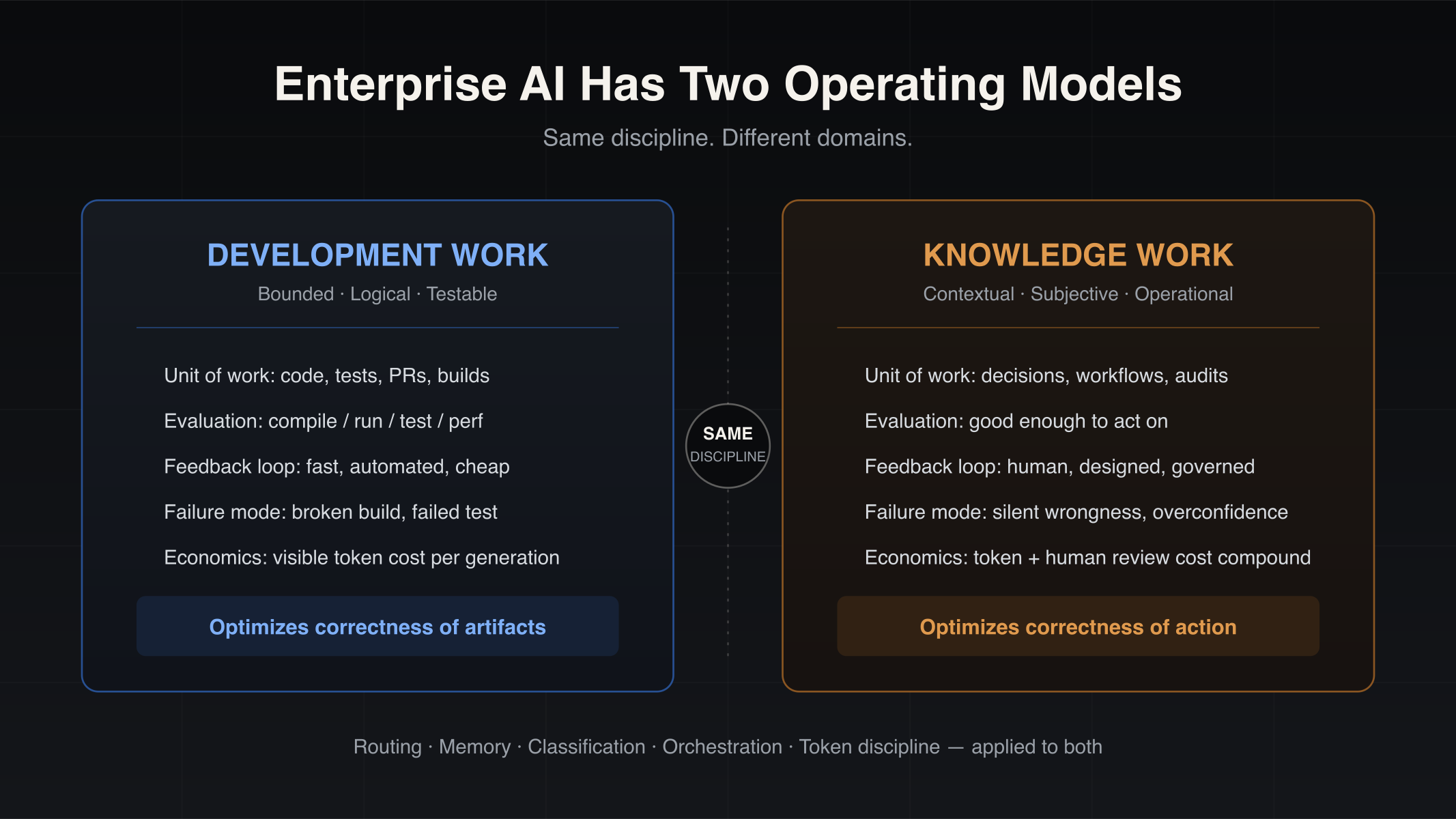
Enterprise AI Has Two Operating Models: Development Work and Knowledge Work
Enterprise AI is splitting into two operating models — development work and knowledge work. Why coding-copilot playbooks stall on operational workflows, and which engineering disciplines transfer.
-
ai
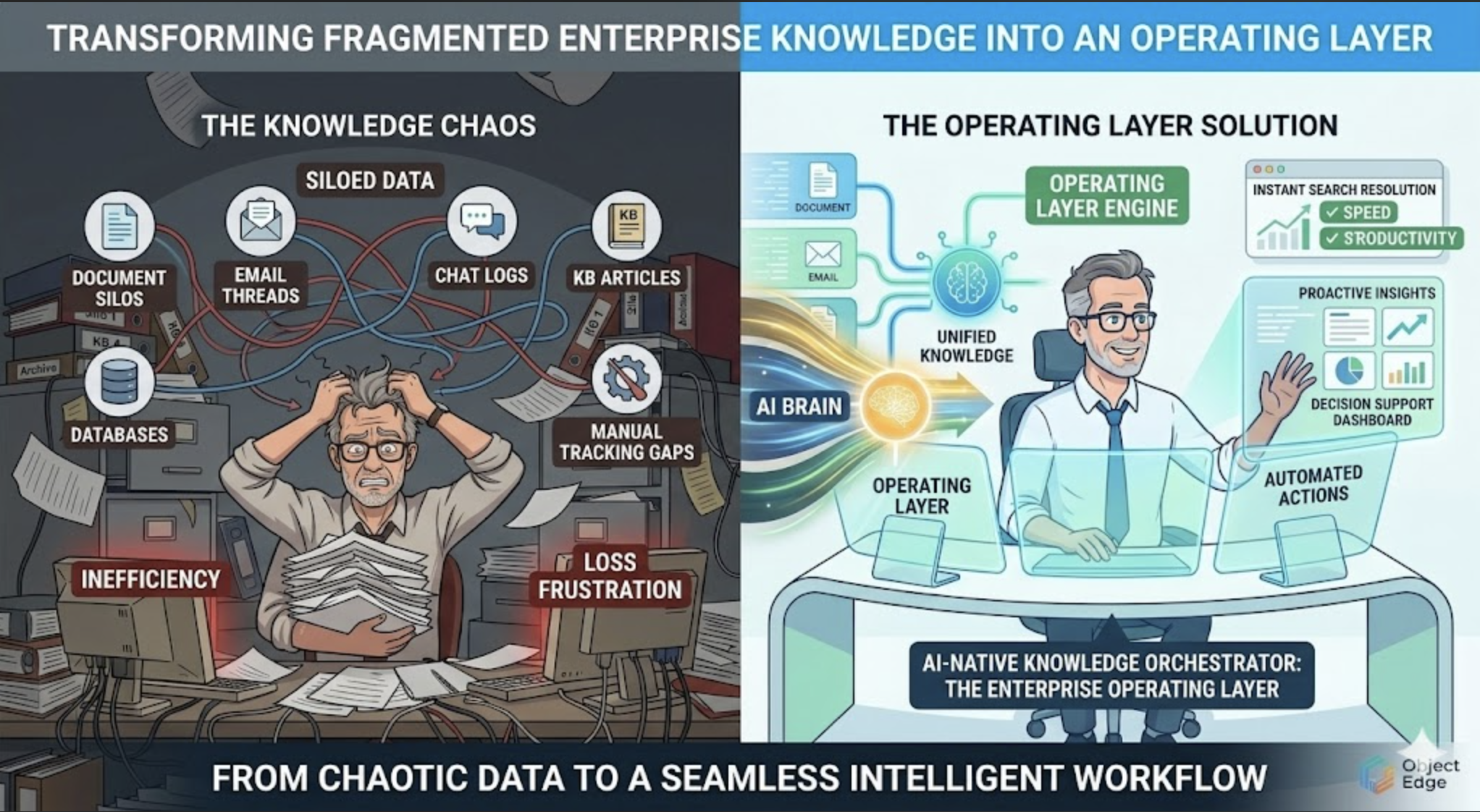
Turn Fragmented Enterprise Knowledge Into an Operating Layer That Teams Can Actually Use
How enterprises unify scattered documents, systems, and tribal knowledge into a searchable, governed operating layer that improves speed, consistency, and decision-making.
-
ai
The End of Subsidized Tokens Is Coming. Plan Accordingly.
The era of artificially cheap AI tokens is ending. Here is why token efficiency is becoming architecture, and how enterprises should plan a model portfolio strategy before prices spike.