ai
Turn Fragmented Enterprise Knowledge Into an Operating Layer That Teams Can Actually Use
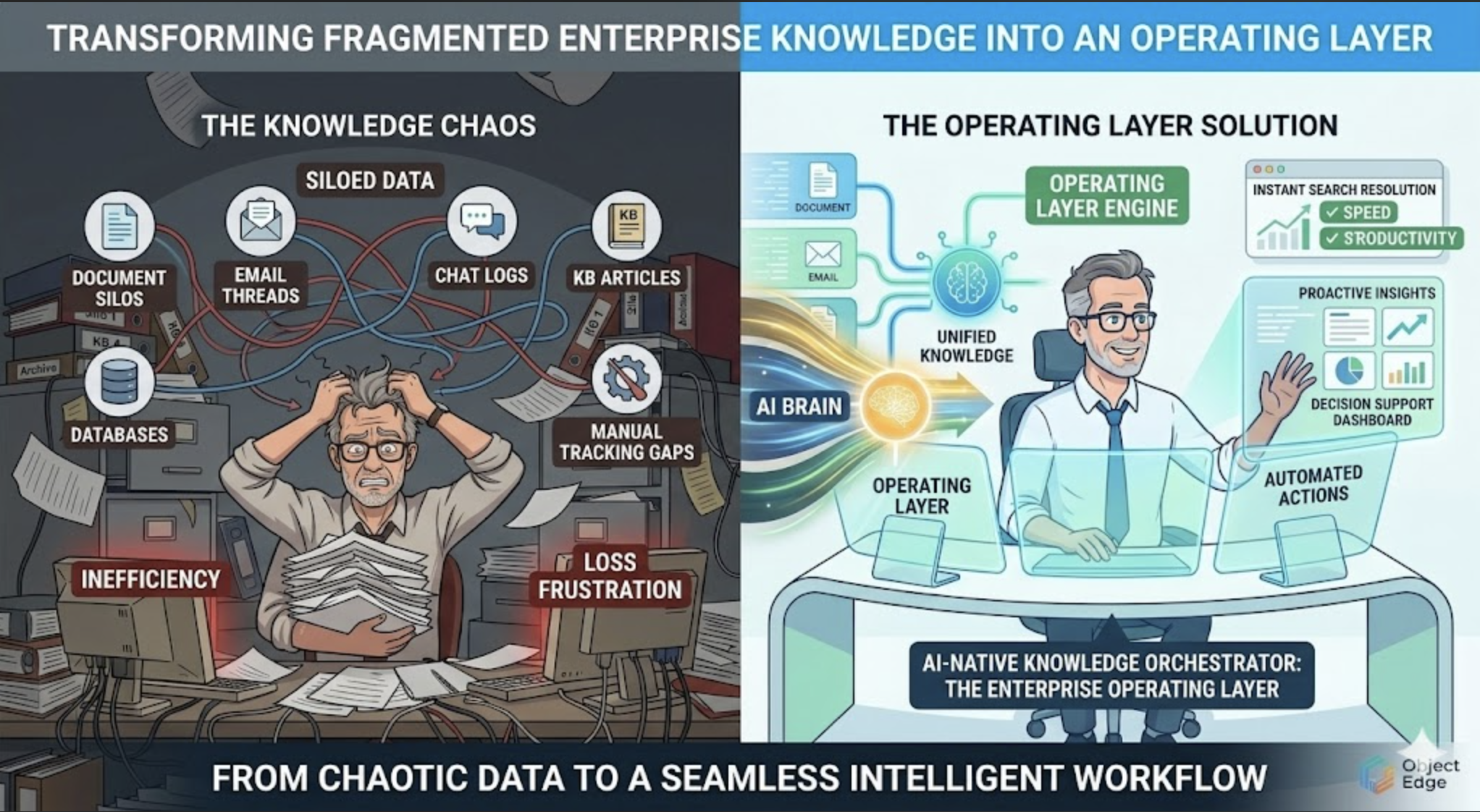
Enterprises do not have a knowledge problem. They have a fragmentation problem.
The average organization stores critical information across SharePoint, Confluence, Google Drive, Slack, Jira, ServiceNow, CRM notes, email threads, and custom internal tools. The result is predictable: teams waste time searching, answers conflict, and decisions depend on who happens to know where the information lives.
That fragmentation is expensive. In many enterprises, knowledge workers spend 20 to 30 percent of their week just finding, validating, and reassembling information. For a 1,000-person organization, that is thousands of hours every month lost to search friction, duplicate work, and avoidable escalations.
The fix is not another repository.
The fix is a usable operating layer: a unified knowledge system that connects fragmented sources, preserves governance, and makes trusted answers available in the workflows people already use.
Fragmented knowledge breaks execution
When knowledge is scattered, the cost shows up in operations first.
Engineering teams ship slower because design decisions are buried in old tickets or private Slack threads. Operations teams make inconsistent calls because the latest SOP lives in a PDF no one opens. Support teams escalate too much because policy changes are not synchronized across systems. Leadership loses visibility because reports are assembled manually from multiple sources, each with different definitions.
This is not just inefficient. It creates operational risk.
Common failure patterns include:
- Duplicate work because teams cannot find prior decisions
- Inconsistent customer responses because source-of-truth content is unclear
- Slower onboarding because new hires must learn the organization through tribal knowledge
- Bad AI outputs because the underlying content is incomplete, stale, or ungoverned
- Compliance gaps because policies exist, but no one can verify the current version quickly
If you are trying to deploy AI on top of a fragmented knowledge base, the model does not fix the problem. It amplifies it.
What a knowledge operating layer actually is
A knowledge operating layer is not a document portal and not a chatbot wrapper around your file store.
It is the structured layer that sits between enterprise systems and the people or AI agents consuming information. Its job is to make knowledge usable, trustworthy, and current.
A real operating layer does four things:
-
Connects sources It pulls from systems where knowledge already exists: wikis, shared drives, ticketing systems, CRMs, repositories, and communications platforms.
-
Normalizes meaning It resolves duplicate titles, conflicting versions, broken references, and inconsistent terminology so the same concept means the same thing across teams.
-
Applies governance It controls access, enforces metadata, tracks provenance, and preserves auditability so content can be trusted in regulated environments.
-
Serves knowledge in context It delivers answers inside the tools people already use, instead of forcing them to learn yet another destination.
This is the difference between storage and operational intelligence.
The business case: speed, consistency, and leverage
Enterprises unify knowledge for one reason: they want better execution at lower cost.
The gains show up in measurable ways:
- Faster resolution times when employees and support teams can access verified answers immediately
- Lower onboarding time when new hires are guided by a single operational knowledge layer instead of scattered tribal expertise
- Reduced rework when teams can find approved decisions instead of recreating them
- Better AI performance when retrieval is grounded in governed, current enterprise content
- Higher compliance confidence when answers are traceable to source documents and ownership is clear
In practical terms, even a modest improvement matters. If an enterprise reduces average search and validation time by 10 minutes per employee per day across 500 knowledge workers, that saves more than 20,000 hours annually. At 30 minutes per day, the number becomes a major productivity gain, not a marginal optimization.
That is why leading organizations treat knowledge architecture as infrastructure.
Why most knowledge initiatives fail
Most enterprises try to solve fragmentation by adding another layer of content.
They launch a new wiki, ask teams to “keep it updated,” or deploy a search tool without fixing the underlying architecture. The outcome is familiar: adoption is low, content drifts, and the new platform becomes one more place to check.
The failure usually comes from five issues:
1. No source-of-truth model
If ownership is unclear, content diverges quickly. Teams need a defined system for authoritative sources, not a loose content commons.
2. Weak information architecture
Without a standard taxonomy, content discovery fails. People can only find what they already know exists.
3. No lifecycle management
Knowledge changes. Policies, procedures, engineering decisions, and product guidance all expire. If the system does not manage freshness, trust collapses.
4. Poor integration
Employees do not want another destination. They want answers in Slack, Teams, portals, dashboards, and service tools.
5. AI without governance
AI retrieval systems are only as good as the knowledge graph, metadata, and access controls behind them. If those are weak, hallucinations and permission leaks become operational issues.
A usable operating layer avoids all five.
What technical buyers should look for
If you are a CTO, VP Engineering, or VP Operations, the question is not whether knowledge should be unified. It is how to do it without creating another brittle platform.
Look for a solution that can:
- Ingest from multiple enterprise systems without requiring manual reauthoring
- Preserve document lineage and content provenance
- Enforce role-based access and security boundaries
- Support metadata, taxonomy, and ownership rules
- Surface context-aware answers in operational workflows
- Scale across teams without creating content sprawl
- Support both human users and AI agents with governed retrieval
The architecture matters. A knowledge layer that cannot explain where an answer came from, who owns it, and whether it is current is not enterprise-ready.
Where Object Edge fits
Object Edge helps enterprises move from fragmented content to usable knowledge systems that support execution.
That means designing the knowledge architecture, not just deploying tools. It means connecting the systems you already rely on, establishing governance, and building a layer that can serve both people and AI with confidence.
This is especially important now, as enterprises move from experimentation to operational AI. The organizations that win will not be the ones with the largest model. They will be the ones with the cleanest knowledge layer.
Because once knowledge is structured, governed, and connected, AI becomes useful. Without that layer, AI just accelerates confusion.
The outcome: one enterprise, one operating layer
When knowledge is unified correctly, the enterprise changes in visible ways.
Teams spend less time searching and more time executing.
Decisions get documented once and reused many times.
Onboarding becomes repeatable.
Support gets faster.
Operations get more consistent.
Leadership gets cleaner visibility.
And AI stops guessing.
That is the practical value of knowledge architecture: not more content, but better execution.
If your enterprise is sitting on thousands of disconnected documents, procedures, decisions, and institutional memories, the next step is not another repository. It is an operating layer that makes all of that knowledge usable.
Build the layer before you scale the chaos
If your organization is ready to turn fragmented knowledge into a governed, AI-ready operating layer, Object Edge can help.
Start with the main website CTA and talk to our team about knowledge architecture, enterprise search, and operational AI foundations.
Related articles
-
ai
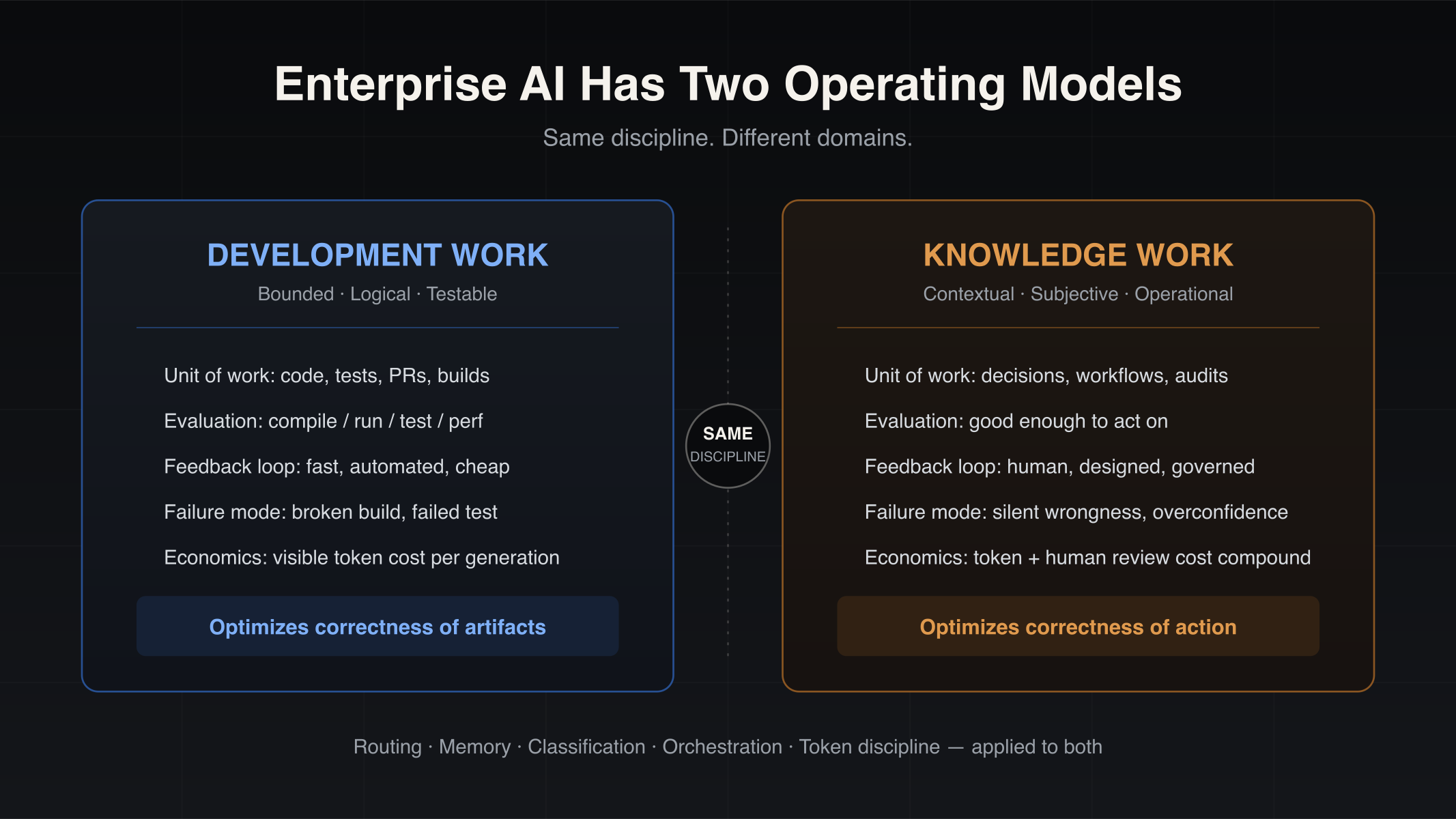
Enterprise AI Has Two Operating Models: Development Work and Knowledge Work
Enterprise AI is splitting into two operating models — development work and knowledge work. Why coding-copilot playbooks stall on operational workflows, and which engineering disciplines transfer.
-
ai
Tokenomics Is the New AI Efficiency Frontier — and Here's How We're Winning It
AI tokenomics is the discipline of managing token consumption at enterprise scale. Learn how semantic infrastructure, context-aware retrieval, and agent budgeting cut AI costs without sacrificing quality.
-
ai
The End of Subsidized Tokens Is Coming. Plan Accordingly.
The era of artificially cheap AI tokens is ending. Here is why token efficiency is becoming architecture, and how enterprises should plan a model portfolio strategy before prices spike.