ai
The End of Subsidized Tokens Is Coming. Plan Accordingly.
I’ve written about this before: we are living through a temporary era of artificially cheap intelligence.
For the last couple of years, most companies have been able to treat model usage as if it were a rounding error. That was never going to last. Recent pricing moves from OpenAI and others — and Microsoft Copilot reportedly driving the cost of leveraging premium models like Opus up by 600%+ in some workflows — are the clearest signal yet that the subsidy era is ending.
If you are building AI-heavy workflows today, this matters a lot more than most teams realize.
The real risk is not just that models get more expensive. It’s that companies will lock themselves into brittle workflows, inflated token patterns, and the wrong model assumptions — only to discover a few months from now that the exact same workflow costs 600% to 1000% more to run.
That is a bad surprise if you are experimenting. It is a disastrous surprise if you are already in production.
Cost discipline is becoming a product capability.
Most teams still evaluate AI systems primarily on output quality. That is understandable, but incomplete. Over the next 12 months, one of the most important competitive advantages in enterprise AI will be the ability to match the right model to the right task, with the right context window, retrieval pattern, and prompt structure.
In other words: token efficiency is no longer an optimization. It is architecture.
This is exactly why we have spent so much time on harness engineering.
A lot of people think the value is in simply plugging into the smartest possible model and routing everything through it. That works when usage is subsidized. It stops working when every workflow starts carrying real economic weight.
What matters instead is building systems that can reason about:
- when a frontier model is actually necessary,
- when a much cheaper model is good enough,
- when the answer should come from retrieval rather than generation,
- when context should be compressed, summarized, or structured before inference,
- and when the workflow itself should be redesigned to consume fewer tokens.
That is the difference between a cool demo and a sustainable operating model.
Use the expensive models where they matter.
To be clear, we absolutely use expensive models.
We often leverage the best available models for development work, design of complex systems, and the kinds of higher-ambiguity tasks where frontier reasoning still creates disproportionate value.
But that does not mean every production knowledge workflow should run on the most expensive model available.
In fact, for our actual knowledge work, we are now routinely using models that cost roughly 1/100th the price of Opus-class models for a meaningful share of production traffic. The result is not lower ambition. The result is better economics.
The point is not to avoid frontier models. The point is to deploy them selectively.
What this looks like in practice.
In our latest Sayya release, running on top of Hive — our enterprise knowledge graph layer — we are routinely supporting roughly 100 employees for about $40 per day.
Do the math:
- ~$40/day
- ~$1,200/month
- ~$12 per user per month
- ~$0.44/million tokens
And this is not lightweight usage.
These are heavy knowledge workflows — the kind of work many people instinctively assume must be done with the most expensive closed models. It includes indexing, retrieval, and operational knowledge access across the environment. That means pulling from email, chat, and structured systems like HubSpot and NetSuite, then grounding responses and actions in that enterprise context.
That is a very different cost profile than the one many companies are quietly drifting toward.
The next pricing shock is not hypothetical.
In my last piece, I argued that Claude Code for power users will likely exceed $1,000 per month and could approach $10,000 per month within a year.
I still believe that.
And I think this dynamic is going to spread across the board.
Why? Because there is only so long model providers can subsidize real usage at current levels — especially as demand rises into hard physical constraints. This is not just a software pricing question. It is a compute and infrastructure question. Data center buildout takes time. GPU supply is finite. And ultimately, the electricity grid is a real constraint on how fast this category can scale.
At some point, pricing has to reflect physics.
When that happens, the companies that treated token usage like free bandwidth will get hurt first.
Why we are investing in our own infrastructure.
This is also why we have started hosting models on our own GPUs.
Not because open-weight models are universally better. They are not.
Frontier models still outperform open models in many important cases, especially where reasoning depth, coding quality, or nuanced instruction following really matter.
But the gap is closing in a way that is strategically useful.
What we are seeing now is that open-source and self-hosted models are already good enough to handle perhaps 20% to 30% of the workload in enterprise knowledge systems. That does not mean they replace frontier models. It means they can absorb a meaningful share of volume at dramatically better economics.
That matters.
Because once you can take even 20% to 30% of your workload and route it intelligently, you have options:
- lower blended cost,
- less vendor lock-in,
- more control over data and latency,
- and a more resilient long-term AI operating model.
The mistake to avoid right now.
The biggest mistake companies can make in this moment is to optimize only for immediate output quality and speed of deployment.
Yes, get into production. Yes, move quickly. Yes, learn by doing.
But while you are doing that, also start building the discipline of token governance:
- measure token consumption by workflow,
- separate dev usage from production usage,
- classify tasks by model requirement,
- design fallback paths,
- test smaller and open-weight models early,
- and build retrieval and memory systems that reduce unnecessary generation.
If you wait until prices spike, it will be too late. By then your workflows, user habits, and internal expectations will already be fixed.
The right time to optimize token utilization is before you are forced to.
The future belongs to teams that treat intelligence like a portfolio.
We are moving out of the era where one giant model sits at the center of every workflow.
The winning pattern will be orchestration:
- expensive models for high-value, high-ambiguity tasks,
- cheaper models for repeatable knowledge work,
- open models where they are good enough,
- retrieval systems to minimize unnecessary inference,
- and harness engineering to route work intelligently.
That is the real architecture of AI economics.
The era of subsidized tokens is ending. The era of model portfolio management is beginning.
The companies that learn that now will have a massive advantage over the ones that learn it after their AI bill explodes.
Contact us to talk about building a token-efficient AI architecture for your enterprise.
Related articles
-
ai
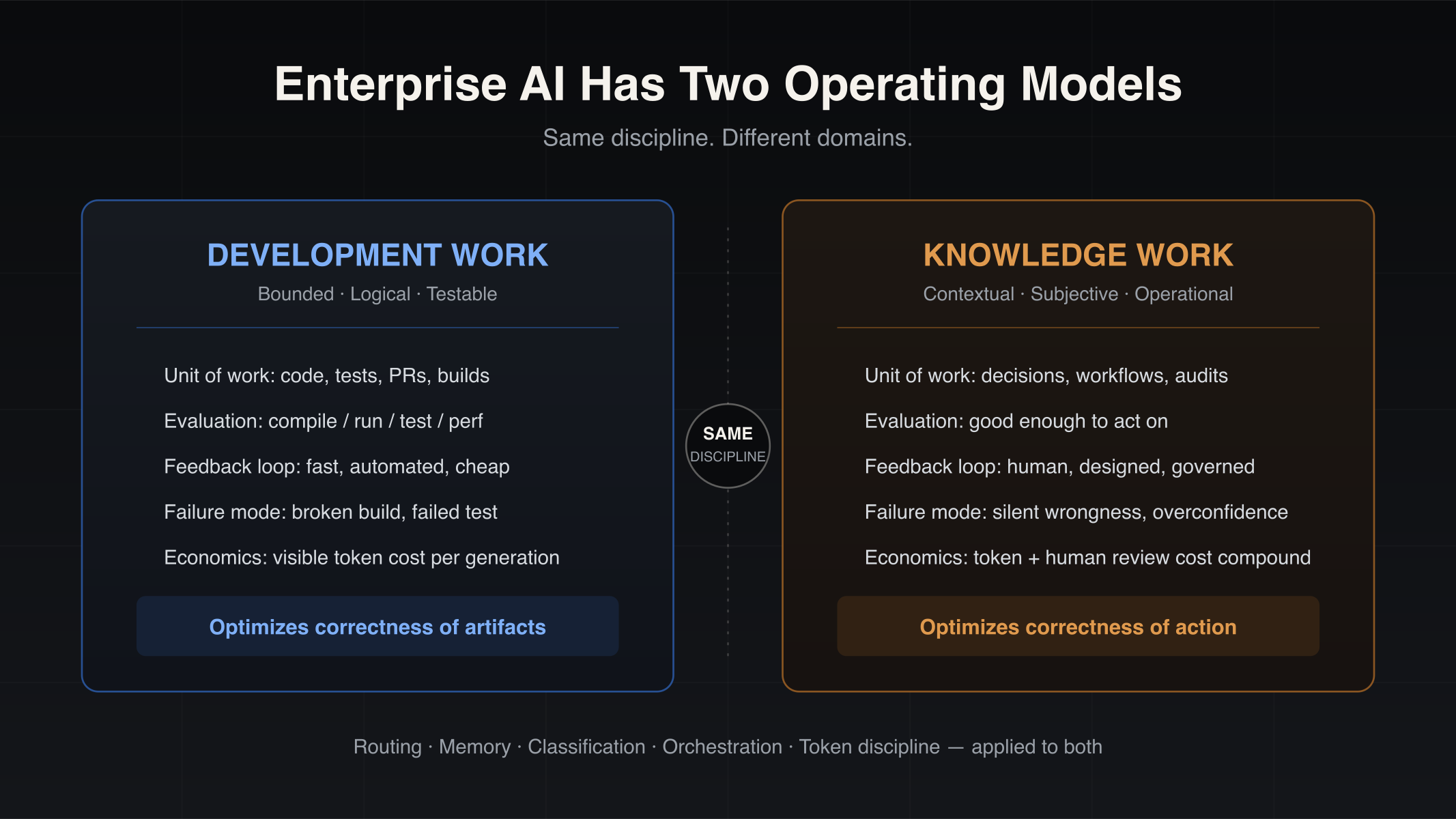
Enterprise AI Has Two Operating Models: Development Work and Knowledge Work
Enterprise AI is splitting into two operating models — development work and knowledge work. Why coding-copilot playbooks stall on operational workflows, and which engineering disciplines transfer.
-
ai
Tokenomics Is the New AI Efficiency Frontier — and Here's How We're Winning It
AI tokenomics is the discipline of managing token consumption at enterprise scale. Learn how semantic infrastructure, context-aware retrieval, and agent budgeting cut AI costs without sacrificing quality.
-
ai
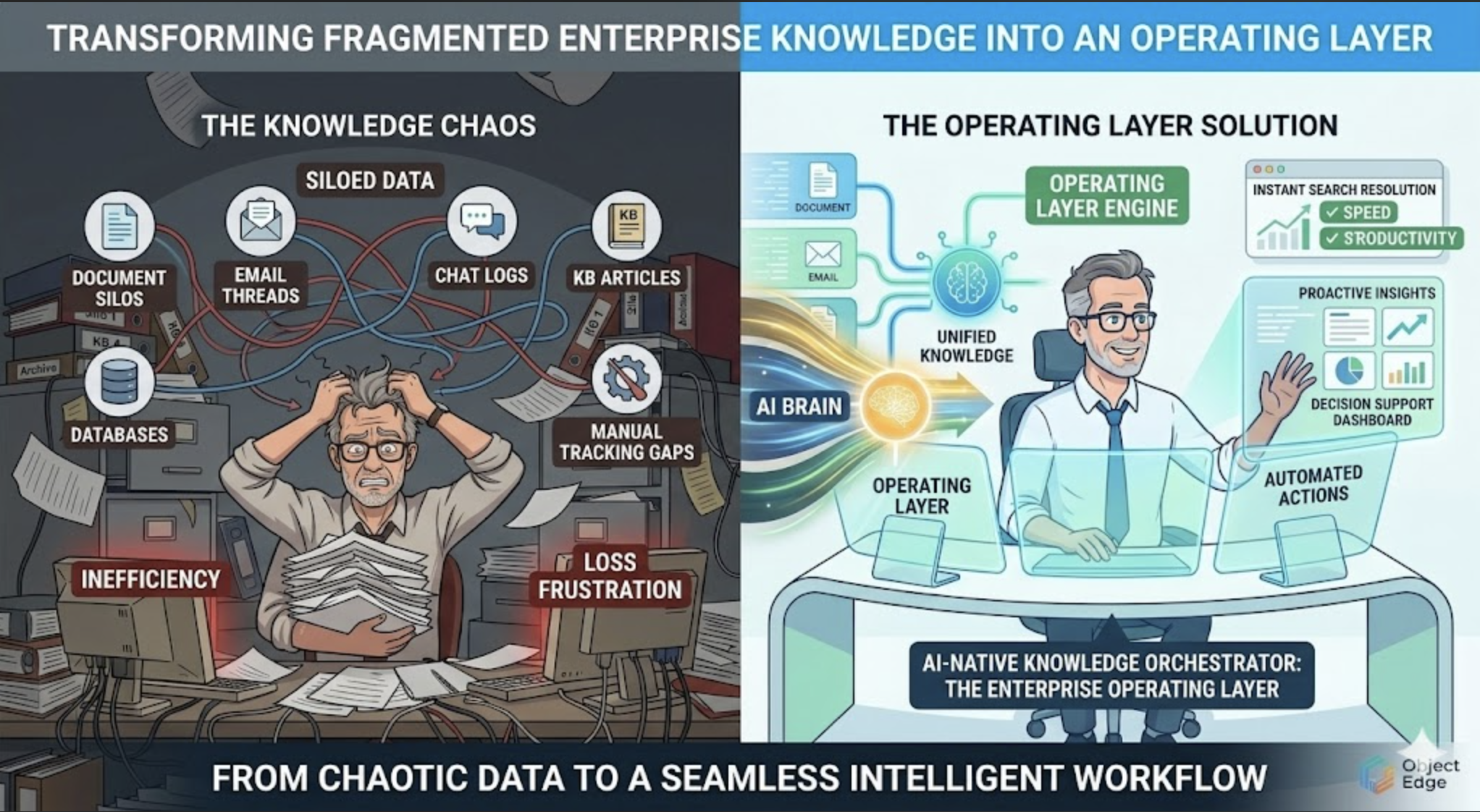
Turn Fragmented Enterprise Knowledge Into an Operating Layer That Teams Can Actually Use
How enterprises unify scattered documents, systems, and tribal knowledge into a searchable, governed operating layer that improves speed, consistency, and decision-making.