ai
AI-Native Knowledge Orchestration: Cut Search Time, Raise Support Accuracy, and Move Faster
AI-Native Knowledge Orchestration: Cut Search Time, Raise Support Accuracy, and Move Faster
Most enterprises don’t have a knowledge problem. They have a fragmentation problem.
Your teams already know where the answers live: Salesforce cases, SAP tickets, Confluence pages, SharePoint folders, Slack threads, email chains, PDF runbooks, and tribal knowledge sitting in someone’s head. The issue is that none of those systems are coordinated. Employees spend time hunting, reconciling, and re-asking the same question in three different places.
The result is expensive and measurable:
- Knowledge workers spend up to 40% of their time searching for information
- Support teams give inconsistent answers because the “source of truth” is spread across systems
- AI initiatives stall because the underlying data is incomplete, duplicated, or stale
- Decision cycles slow down because leaders can’t trust what they find fast enough
AI-native knowledge orchestration fixes the root cause. Instead of forcing people to search system by system, it creates a unified knowledge layer across enterprise content and exposes it through natural language, policy-aware retrieval, and decision intelligence.
At Object Edge, we deploy this layer in 6 weeks so enterprise teams can reduce search time to near-zero, improve support accuracy, and build AI on top of a data fabric that actually works.
Fragmented knowledge is a business problem, not an IT inconvenience
Knowledge fragmentation shows up differently depending on the team.
A customer support agent is troubleshooting a renewal issue. The answer exists, but the agent has to check:
- a Salesforce case note from a prior escalation
- a Confluence article that was last updated six months ago
- an SAP order status screen
- an internal email from finance confirming an exception
By the time the agent pieces it together, the customer has already waited too long.
Or take an operations manager preparing for a contract dispute. The supporting documentation is spread across a shared drive, a legal mailbox, and a Jira ticket thread. Nobody can quickly identify the latest approved version.
Or engineering is asked to estimate impact for a product change. The relevant context lives across release notes, incident reports, architecture docs, and Slack. People spend an hour locating context before they can spend 10 minutes making the decision.
This is what fragmented knowledge looks like in practice:
- Duplicate answers with subtle differences
- Outdated documentation treated as authoritative
- High-value context trapped in unstructured content
- Experts interrupted for answers that should have been self-service
- AI models pulling from partial, conflicting, or low-trust inputs
The cost is not just search time. It is slower onboarding, lower case resolution quality, more escalations, and worse decisions.
Why internal search keeps failing
Most enterprise search tools were designed to index documents, not understand decisions.
They can return a list of results. They cannot reliably answer:
- Which version is current?
- Which source is authoritative?
- Does this content apply to this region, product line, or customer tier?
- What changed since last quarter?
- What supporting evidence exists across systems?
That is why “search” often becomes another layer of frustration. Users know the answer exists, but the system cannot resolve context.
AI-native orchestration changes the model. It does not just retrieve text. It connects identity, metadata, permissions, document lineage, timestamps, and business context so the answer is assembled from the right sources in the right order.
The practical difference is simple:
- Traditional search gives you documents
- Knowledge orchestration gives you usable answers
For technical buyers, that distinction matters. If your systems cannot establish trust, freshness, and access control at retrieval time, you are not solving knowledge access. You are just adding another index.
How orchestration unifies knowledge across enterprise systems
AI-native knowledge orchestration sits above your source systems and connects them into a single operational layer.
That means content can be unified across:
- Salesforce cases and account history
- SAP orders, invoices, and fulfillment records
- Confluence and SharePoint documentation
- Email threads and attachments
- Tickets, incident reports, and workflow records
- Chat and collaboration systems where institutional knowledge often appears first
The orchestration layer does three things well:
1. Normalizes content without flattening meaning
Enterprise content is messy. A support case is not the same as a policy doc, and neither is the same as an email from finance.
Orchestration preserves source-specific structure while standardizing what matters operationally:
- document type
- owner
- timestamp
- business unit
- customer or product context
- permissions
- confidence and freshness signals
This makes it possible to compare and rank across systems without losing nuance.
2. Resolves identity and context
The same customer may appear differently in Salesforce, SAP, and support tooling. The same process might be described differently by operations and engineering.
A knowledge layer uses entity resolution and context mapping to tie those references together. That means a user asking, “What’s the current fulfillment status for Acme?” can get a single answer grounded in order data, case history, and related internal notes.
3. Applies policy-aware retrieval
Not every employee should see every answer. Orchestration enforces permissions at the retrieval layer, not after the fact.
That matters for regulated industries, customer data, internal financials, and role-based knowledge access. If the system cannot honor access control, it cannot be trusted in production.
What changes for support, operations, and engineering
The value of knowledge orchestration is not abstract. It shows up in day-to-day execution.
Support accuracy improves
Support teams waste time because the answer is split across product docs, prior cases, and internal escalation notes. With orchestration, agents can surface the latest approved answer with supporting context in seconds.
Expected impact:
- faster first response
- fewer incorrect resolutions
- lower escalation volume
- more consistent answers across agents and regions
Even a small reduction in rework compounds quickly. If 500 agents save 15 minutes per shift, that is more than 31,000 hours per year returned to the business.
Employee productivity increases
Employees do not want “AI” in the abstract. They want less time searching.
When a knowledge layer can answer questions across systems, teams stop wasting time on manual triage:
- “What did we promise this customer?”
- “Which runbook applies here?”
- “Has this exception already been approved?”
- “What changed in the latest policy update?”
- “Who owns this process now?”
If your workforce currently spends 40% of its time searching, even a 60%+ reduction in decision time is transformational. People shift from finding information to acting on it.
AI initiatives move faster
Most AI projects fail for the same reason: the input layer is bad.
A chatbot over fragmented content produces fragmented answers. A copilot over stale docs becomes a liability. A decision engine without unified data fabric cannot be trusted.
Knowledge orchestration gives AI programs a foundation:
- governed retrieval
- trusted source ranking
- unified enterprise context
- reusable embeddings and metadata
- faster path from pilot to production
That is how AI initiative time-to-production improves by 4x faster: less plumbing, less manual curation, fewer brittle point integrations.
What a six-week deployment actually delivers
A good orchestration program should not take a year to show value.
In six weeks, the goal is to move from disconnected repositories to a live knowledge layer that supports real workflows. That typically includes:
- identifying high-value sources
- mapping identity, metadata, and permissions
- connecting structured and unstructured systems
- classifying content by trust and freshness
- enabling cross-system semantic search
- exposing answers in the tools people already use
The point is not to replace every system of record. It is to make them useful together.
That matters because enterprises do not need more content. They need less friction.
The practical test for your organization
If you want to know whether your enterprise has a knowledge orchestration problem, ask these questions:
- How long does it take a support agent to find the right answer across multiple systems?
- How often do employees ask the same question in different channels?
- How much of your documentation is outdated, duplicated, or unowned?
- Can your AI tools distinguish between authoritative and informal content?
- Can you trace an answer back to trusted sources in under five seconds?
If the answer to any of those is “not really,” your organization is paying a hidden tax on knowledge fragmentation.
Build the knowledge layer your AI strategy depends on
AI-native knowledge orchestration is not a nice-to-have search upgrade. It is infrastructure for faster decisions, more accurate support, and better employee output.
If your teams are still stitching together answers from Salesforce, SAP, Confluence, email, and chat, they are spending too much time on retrieval and not enough on execution.
O
Related articles
-
ai
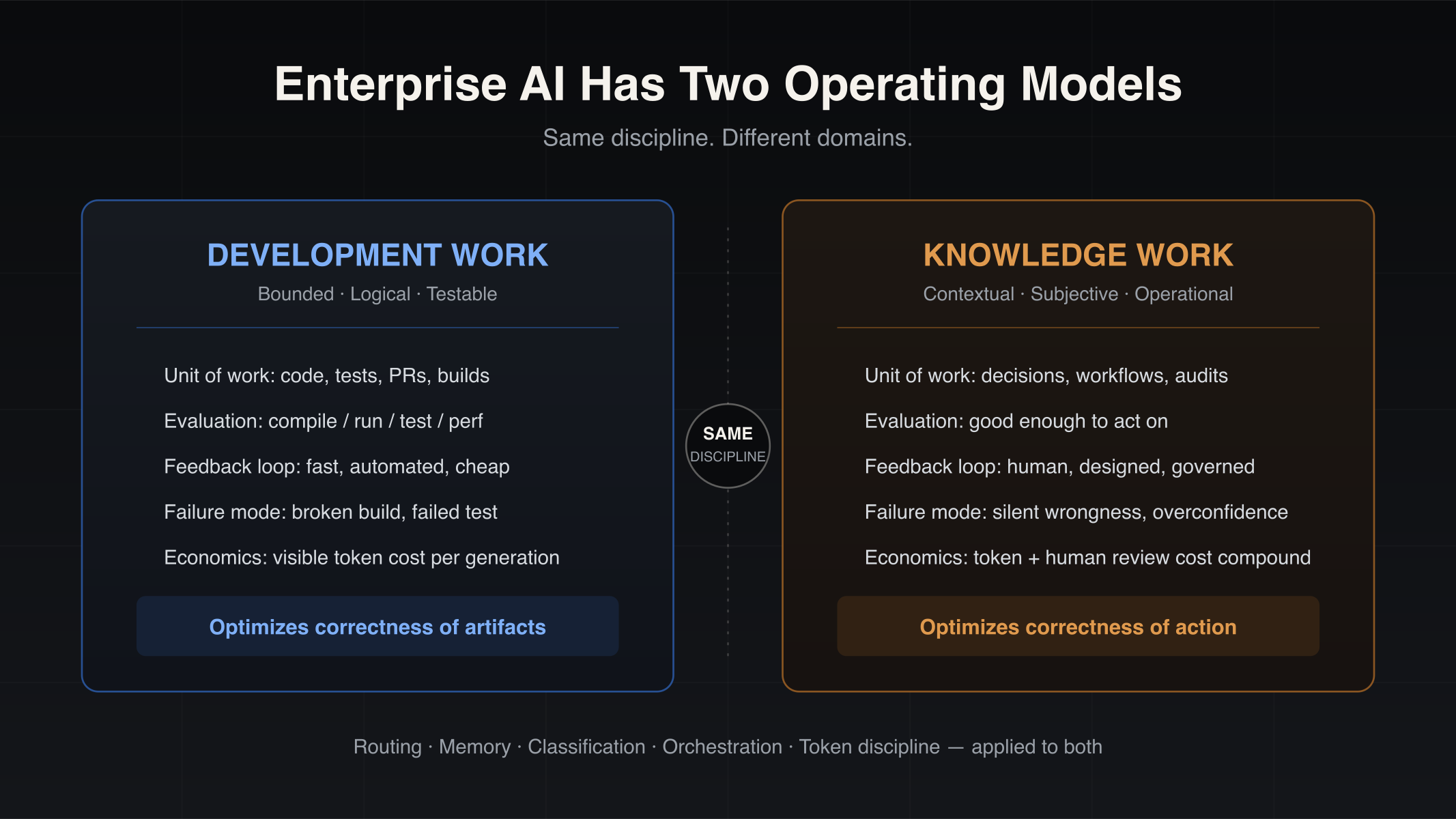
Enterprise AI Has Two Operating Models: Development Work and Knowledge Work
Enterprise AI is splitting into two operating models — development work and knowledge work. Why coding-copilot playbooks stall on operational workflows, and which engineering disciplines transfer.
-
ai
Tokenomics Is the New AI Efficiency Frontier — and Here's How We're Winning It
AI tokenomics is the discipline of managing token consumption at enterprise scale. Learn how semantic infrastructure, context-aware retrieval, and agent budgeting cut AI costs without sacrificing quality.
-
ai
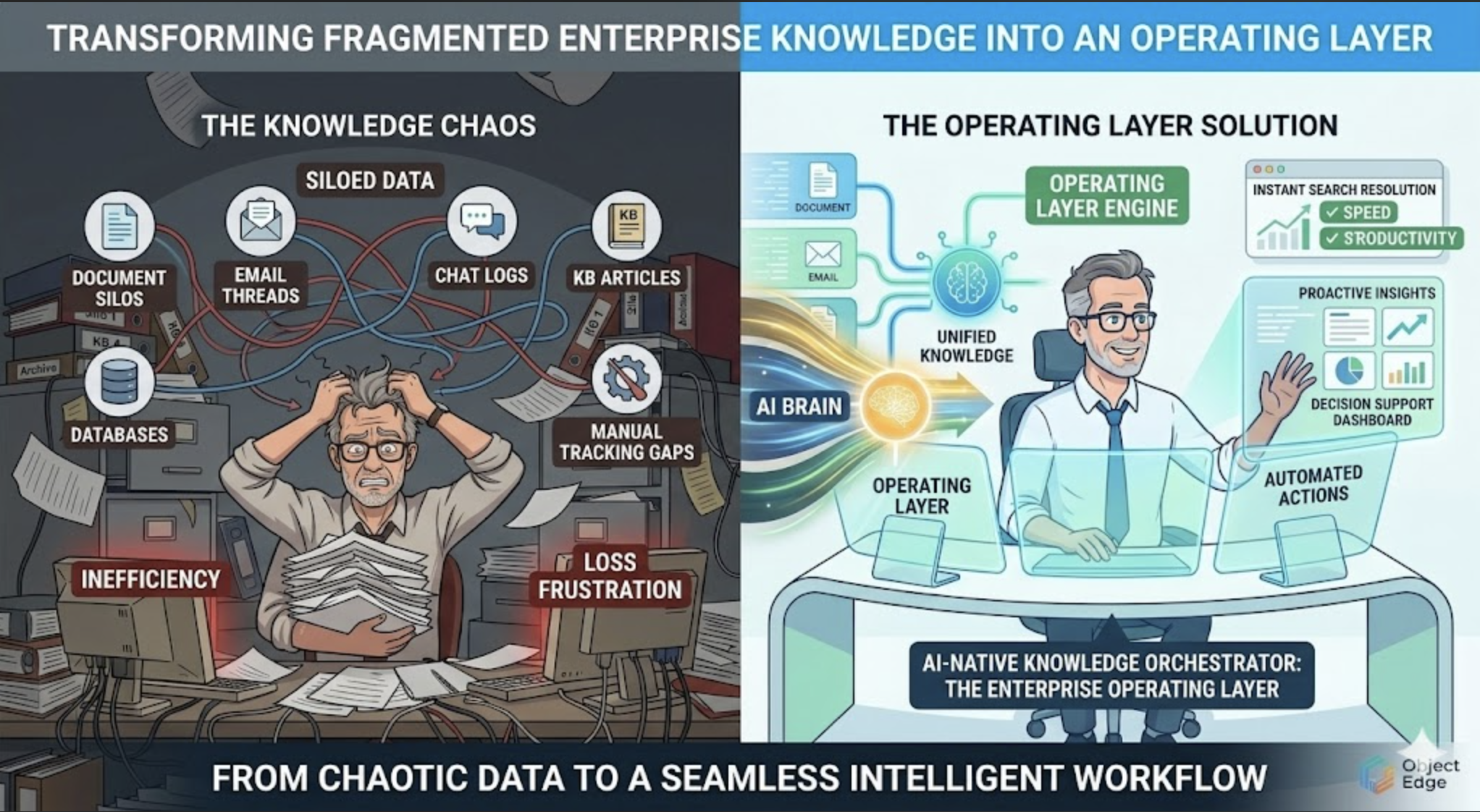
Turn Fragmented Enterprise Knowledge Into an Operating Layer That Teams Can Actually Use
How enterprises unify scattered documents, systems, and tribal knowledge into a searchable, governed operating layer that improves speed, consistency, and decision-making.